They rebuilt our payment infrastructure in 6 weeks with zero downtime. 94% latency improvement. We went from dreading deployments to shipping daily.
Scaling a Payment System from
Failure Under Load to 99.99% Uptime
Zero-downtime migration for high-volume payment infrastructure — rebuilt in 6 weeks using Kafka, Kubernetes, and Redis.
94%
Latency Cut
10x
Throughput
99.99%
Uptime
6wk
Delivery
12+ infrastructure rebuilds delivered
Zero client downtime events
UK · EU · US · AU
Key Results at a Glance
94%
Latency Reduction
10x
Throughput Increase
99.99%
Uptime · Zero Downtime
Project Snapshot
Industry
Payment Infrastructure
Timeline
6 Weeks
Tech Stack
Kafka · Kubernetes · Redis
Core Problem
System failure under peak load
Outcome
99.99% Uptime
The Problem
A Payment System That Couldn't Survive Its Own Success
The platform processed transactions reliably at steady state. Under peak load — end-of-month billing cycles, promotional bursts — the architecture collapsed. Failures weren't random. They were structural.
The team had reached the ceiling of vertical scaling. Every attempted horizontal scale event introduced race conditions, inconsistent state, and manual rollback procedures. Each deployment was a risk event.
P99 Latency Spiking to 800ms+ Under Load
Redis cache misses cascaded into synchronous database reads during traffic peaks, compounding latency across all dependent services and breaching SLA thresholds.
Transaction Failures Above 2,000 Concurrent Users
Idempotency guarantees broke down at the connection ceiling. Duplicate charges and silent payment failures surfaced — directly impacting revenue integrity and client trust.
No Horizontal Scale Path Without Downtime
Stateful session handling and tight database coupling made horizontal scaling impossible without a maintenance window. Every scale event required a coordinated, disruptive deployment.
Zero Visibility Below the Application Layer
Queue depth, consumer lag, and downstream degradation were invisible until customer-facing failures occurred. There was no predictive signal — only reactive incident response.
Root Cause Analysis
Three Structural Gaps Driving Every Failure
The symptoms were varied. The causes were not. Every failure traced back to the same three architectural decisions made at an earlier scale.
These weren't operational failures — they were baked into the architecture. No amount of tuning would fix them. The system needed to be rebuilt, not patched.
01
Synchronous Coupling Between Core Services
Payment processing, fraud checks, and ledger writes were chained synchronously. A single slow downstream call blocked the entire transaction thread — no circuit-breaking, no async fallback, no timeout strategy.
02
Stateful Infrastructure with No Horizontal Path
Session state was held in-process. Scaling horizontally required session migration, which introduced consistency windows that broke idempotency. The database connection pool was sized for a single node and never re-architected.
03
No Observability Strategy Below the App Layer
Metrics existed at the HTTP layer. Below that — Kafka consumer lag, Redis eviction rates, Postgres lock contention — there was nothing. Incidents were diagnosed post-mortem from logs, not predicted from signals.
The Approach
Rebuild the Load Path. Don't Touch Business Logic.
With the root causes mapped, the path forward was clear — but the constraint was non-negotiable: zero downtime, no API changes, no regression to existing transaction behaviour.
1
Decouple with Kafka Event Streaming
Replaced synchronous service chains with Kafka-backed async event flows. Each service became independently deployable with guaranteed delivery and replay capability.
2
Stateless Services on Kubernetes
Extracted session state to a distributed Redis cluster. Services re-deployed as stateless pods — enabling horizontal pod autoscaling without coordination overhead.
3
Layered Observability Stack
Instrumented Kafka consumer lag, Redis hit/miss rates, and DB connection pool saturation. Predictive alerting configured before thresholds — not after failures.
4
Traffic-Shadowed Blue/Green Cutover
Migrated live traffic using blue/green deployment with shadow mode validation. Zero downtime. Rollback path maintained throughout. Cut over in a 4-minute window.
Kafka: Async Transaction Pipeline
Event-driven processing with at-least-once delivery, consumer group partitioning, and dead-letter queue handling for failed events.
Kubernetes HPA: Auto-Scaling Pods
Horizontal Pod Autoscaler configured on CPU and custom Kafka lag metrics. Scale-out triggered before saturation, not during it.
Redis Cluster: Distributed Session & Cache
Cluster mode with read replicas. Cache warming eliminated cold-start latency spikes. TTL policies enforced consistency without stale-read risk.
Circuit Breakers & Idempotency Keys
Resilience4j circuit breakers on all external calls. Per-request idempotency keys in Redis with 24hr TTL — duplicate transactions impossible at the infrastructure level.
Execution Timeline
How 6 Weeks Actually Looked
A week-by-week breakdown of every phase — from audit to cutover. No ambiguity on what happened when.
Week 1
Audit & Root Cause
Full infrastructure audit. Latency profiling, connection pool analysis, load test replay.
Week 2
Migration Strategy
Architecture blueprint finalised. Blue/green plan approved. Rollback paths documented.
Week 3
Kafka & Redis Build
Async event pipeline live. Redis cluster deployed. Session state extracted from services.
Week 4
Kubernetes & HPA
Stateless pods deployed. Autoscaler configured on Kafka lag metrics. Circuit breakers wired.
W5
Week 5
Shadow Testing
Live traffic mirrored to new stack. Observability validated. Zero divergence confirmed.
W6
Week 6
Cutover & Handoff
4-minute blue/green cutover. Full monitoring handoff. Zero downtime. Zero incidents.
System Design
Architecture After Migration
The rebuilt system separates the transaction intake layer from processing and settlement — each independently scalable, each observable at the infrastructure level.
System Architecture Overview
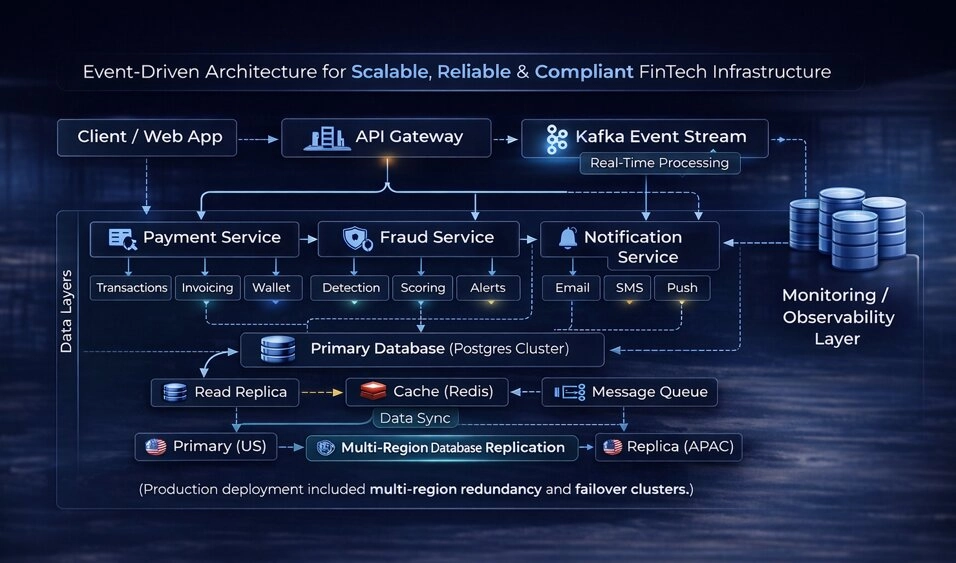
High-level view of the event-driven architecture, showing how requests flow from the API gateway through Kafka event streams into isolated services, with multi-region data replication and observability ensuring reliability and scalability.
Per-Topic Kafka Partitioning
Three partitions per topic with replication factor 3. Consumer group offsets committed after downstream acknowledgement — no message loss under failure.
HPA on Custom Kafka Lag Metrics
Kubernetes autoscaler configured against consumer lag, not just CPU. Pods scale before queues back up — not after latency degrades.
Redis Cluster with Read Replicas
Session store and idempotency key lookup separated into dedicated Redis namespaces. Eviction policies tuned per data type — no cross-contamination under memory pressure.
Dead-Letter Queue with Alerting
Failed events routed to a dedicated DLQ topic with Alertmanager integration. Ops team notified within 30 seconds of first failure — full replay capability retained.
Impact
Measured Outcomes After 6 Weeks
Every number below is from production monitoring — not load tests, not projections.
94%
Latency Reduction
P99 dropped from 800ms to under 48ms. Consistent across peak and off-peak traffic windows.
10x
Throughput Increase
From 2,000 to 20,000+ concurrent transactions without degradation. HPA maintained headroom throughout.
99.99%
Uptime Achieved
Zero unplanned downtime events in 90 days post-launch. Deployments now ship without maintenance windows.
0
Duplicate Transactions
Idempotency enforcement at the infrastructure layer eliminated double-charge incidents entirely.
Client Voices
What Engineering Leaders Say
From the people who lived through the migration — and run the system every day.
The observability stack alone was worth it. We finally know what's happening below the application layer before customers feel it. That's a first for us.
Zero duplicate transactions since go-live. For a payments business that's not a nice-to-have — it's the whole thing. Delivered exactly as scoped, no surprises.
Key Learnings
Engineering Lessons from Scaling a Live Payment System
Patterns applicable beyond this client — relevant to any high-volume, stateful system approaching its scale ceiling.
Decouple Before You Scale
Synchronous service chains don't scale — they amplify failure. Async event-driven design is the prerequisite for horizontal scale, not an optimisation applied afterwards.
Observability Is Architecture, Not Tooling
Dashboards don't give you observability — instrumentation does. What to measure must be decided at architecture time, not retrofitted after incidents occur.
Migration Strategy Is the Critical Path
The re-architecture took 4 weeks. The migration and validation strategy took 2. Blue/green with traffic shadowing isn't overhead — it's the only safe path for live financial systems. Before any migration, we also run closed-platform testing to validate behaviour under real device conditions.
Recognise Any of These Failure Patterns?
15-minute scoping call. NDA signed upfront. Architecture proposal within 48 hours. No pitch. No commitment. Or browse more case studies first.
NDA before any discussion
Proposal within 48 hours
Fixed-scope milestones
No long-term lock-in